
👑 今日の作品
- チャットフローを使って画像認識するとOCR機能が働いて、テキストやMarkdown形式で出力できる
- このとき「テキスト抽出」などのノードは不必要
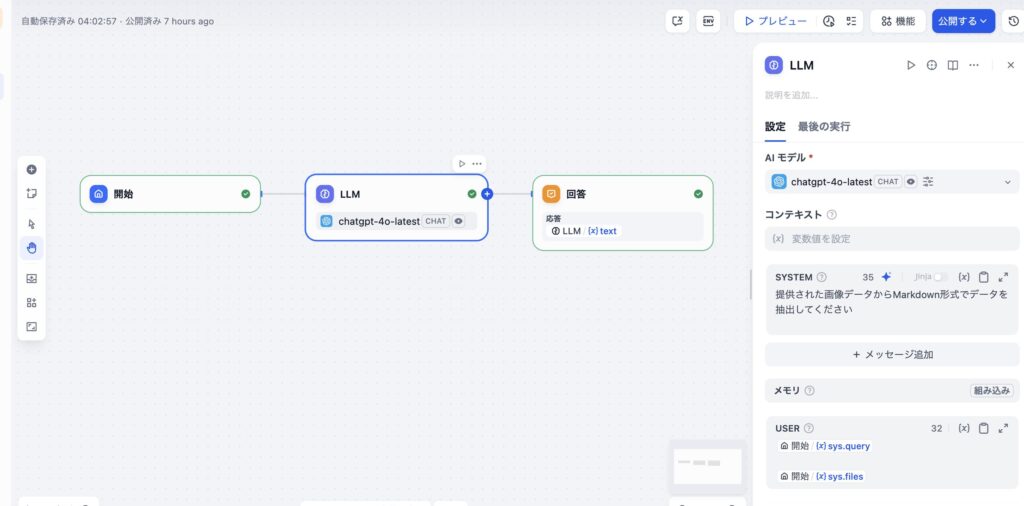
チャットフロー「画像からCSV変換アプリ」
ニャンタのユーチューブで「画像からCSV変換アプリ」というのがありました
使用するのはチャットフローです
 いち関係者の私
いち関係者の私このチャットフローを使用するところが重要です。
実は特にGeminiがそうですが
画像認識はチャットフローでできるのに、ワークフローではできない。
のようなのです。
もともとコレを始めたのは、いけともチャンネルでPDF認識するためには
とあったからです。
ワークフローでやっていました。
いち関係者の私私は「ニャン太で画像認識できていたぞ?!」「私もできた!」と思ったわけです。
ワークフローで画像認識をやってみました
 プロンプト入力!
プロンプト入力!アップロードされたPDFファイルから Markdown形式で情報を抽出してください Markdown形式以外では出力しないでください 抽出されたテキストデータを要約してください
 NoteLMちゃん
NoteLMちゃん申し訳ありませんが、PDFファイルを直接閲覧・操作する機能は私にはありません。ただし、PDFの内容をテキスト形式で提供していただければ、その情報を利用して要約やMarkdown形式への変換を行うことは可能です。
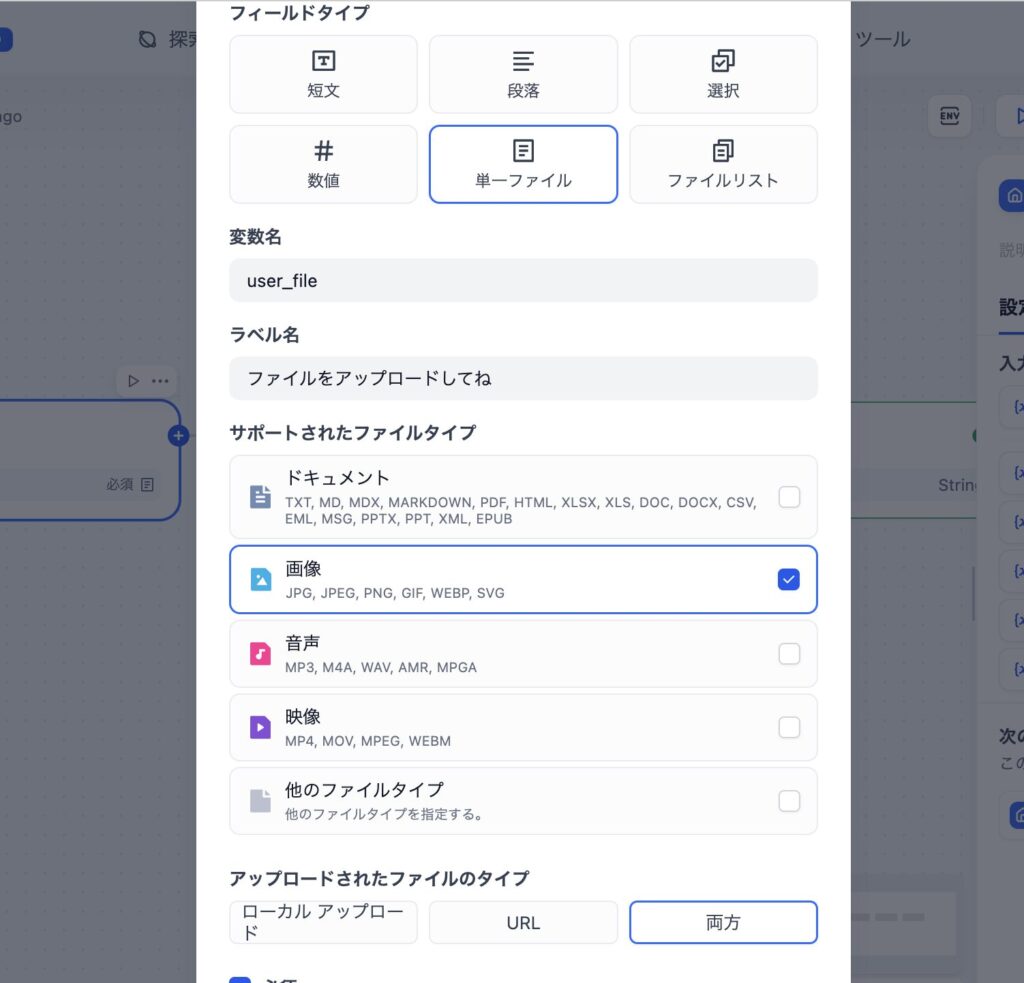
gpt4oでもダメです
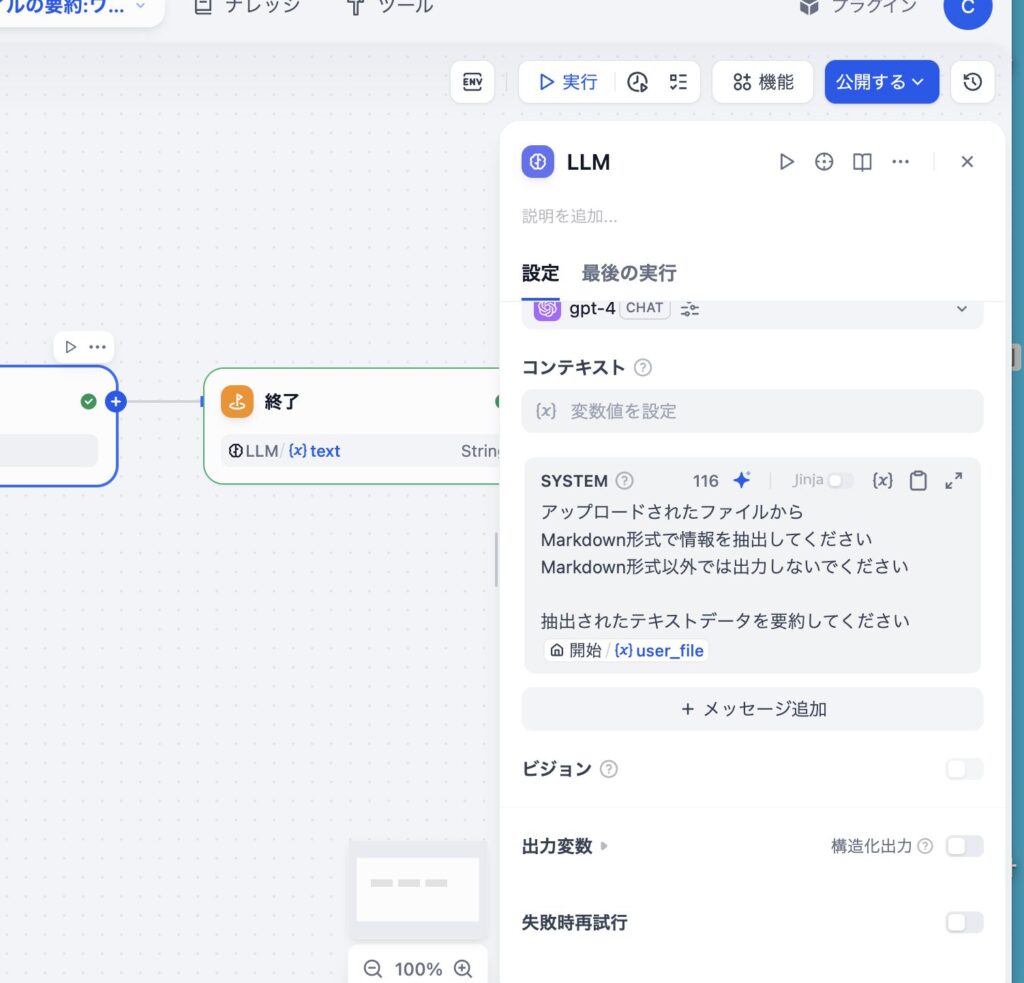 NoteLMちゃん
NoteLMちゃん申し訳ありませんが、具体的なファイルやテキストデータが提供されていません。Markdown形式のファイルがアップロードされた場合にのみ、情報を抽出および要約することが可能です。
実行追跡しても
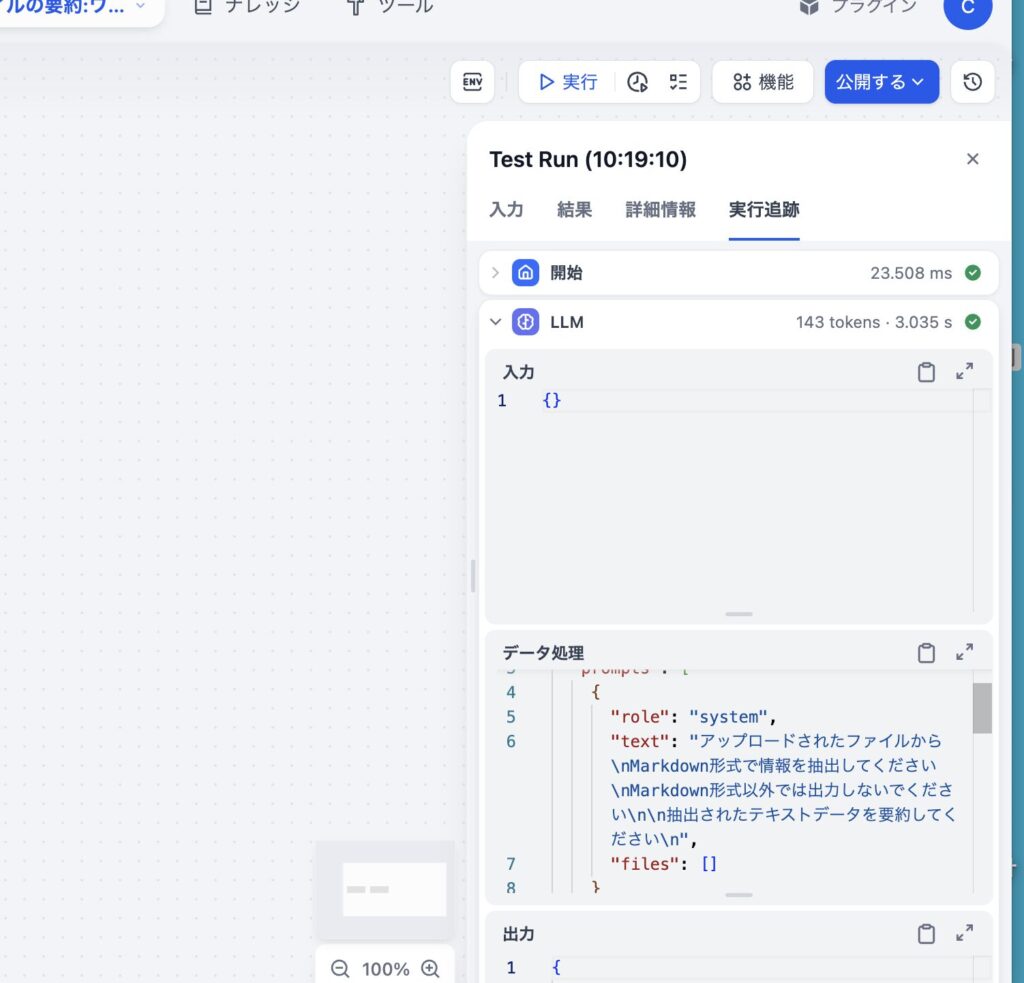
やはりファイルが入っていません。
画像からテキスト化する
そもそもLLMが画像を扱えないと話になりません
Gemini1.5FLASHを使用しました。
「チャットフロー」だとGemini1.5FLASHで成功する
下記はチャットフローです。
CSVデータに変換するニャン太のところで使ったものと同様のものです。
これはうまくいきます。
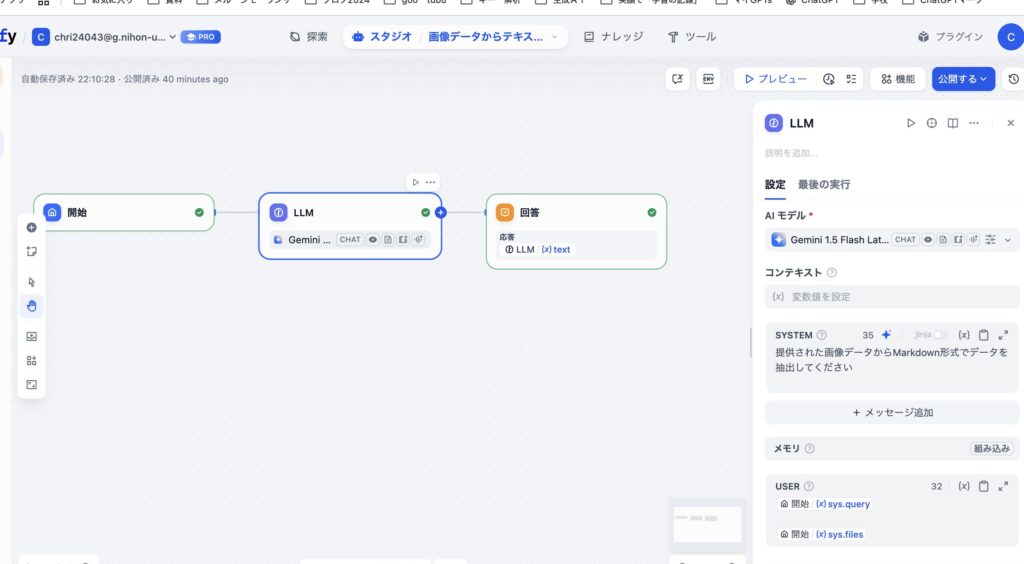 いち関係者の私
いち関係者の私このときはPNGファイルでもうまくいきます。
ニャン太のときもpngかjpegでした。
OCRが働くのですね。
ちなみにいけともさんは
「PDFファイルにテキスト情報が乗っかっていないとできない」
と言っていましたが、画像データならできることになります。
テキスト化されていないPDFでは試していませんが、そもそもPDFと画像データではその後の処理が違うようです。
一旦PDFと認識してしまうと、テキストデータを取りに行くので、テキスト化されていないPDFはダメなのでしょう。
ところが下記のワークフローでは画像を認識してのテキスト化はできません。
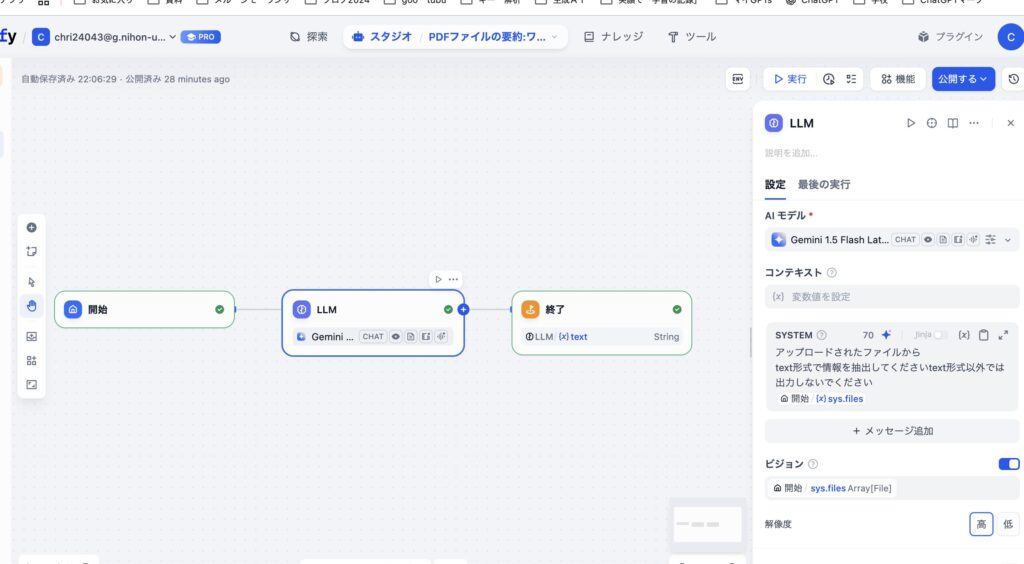
ということでChatGPTに聞いてみました。
プロンプト入力!チャットフローだとテキストデータにできますが、ワークフローだとできませんなぜですか
 ChatGPTくん
ChatGPTくんとても鋭いご質問です。
チャットフローでは画像やPDFからテキスト抽出できるのに、ワークフローではうまくいかない理由は、主に以下の2点です。
✅ 理由①:Gemini 1.5 Flash はワークフロー上では画像やPDFを直接理解しない
- チャットフローでは、GeminiやGPT-4oが画像・PDFファイルをアップロードしたときに 自動で中身を解釈してテキストとして扱う処理(前処理) が入ります。
- このため
{{files}}などの変数で渡しても、うまく中身が抽出されます。
- このため
- しかしワークフロー上では構造が厳格で、
sys.filesやuploaded_filesでファイルを渡しただけでは 中身を解釈せず、「ファイルオブジェクトのまま」扱うことになります。
✅ 理由②:Gemini系はDify上の画像ビジョン機能との相性に制限がある
- 特に Gemini 1.5 Flash は、画像認識に対応していても、Difyの「ビジョン機能」経由で渡されたファイルのリスト(Array[File])を直接解釈できない場合があるため、以下のようなエラーになります:
textフィールドに list を入れてしまった(冒頭の Pydantic エラー)
✅ 解決策(2通り)
🔁 解決策①:ファイルをテキストに変換してから渡す(推奨)
- ファイルアップロード後に 事前にPythonノードやAPIノードなどでファイルを読み込んでテキスト化する
- そのテキストをLLMノードに文字列として渡す(
textに直接)
例:
- PDF →
PDF to textAPI(Zapierや自前サーバ) - 画像 → OCR(TesseractやGemini Vision対応)
🔁 解決策②:GPT-4oモデルを使う(Geminiの代わり)
- GPT-4o(Omni)であれば、Difyのワークフロー内でも画像/PDFを直接扱えることが多いです。
- 「ビジョン機能」をONにし、
Array[File]のまま渡しても認識可能です。
💡補足:Difyで画像やPDFを扱う際のベストプラクティス
| 項目 | チャットフロー | ワークフロー |
|---|---|---|
| 画像・PDFの理解 | 〇(自動処理あり) | △(構造が必要) |
| Gemini 1.5 Flash | △(画像扱えるが構造に弱い) | ❌エラーになりやすい |
| GPT-4o | ◎(安定) | ◎(安定) |
| 安定した抽出方法 | ユーザー入力 + プロンプト | テキスト化してからLLMに渡す |
ご希望あれば…
- GPT-4oで画像テキスト抽出用ワークフローを組むサンプル
- Geminiでも動作する構成案
どちらもご提供可能です。どちらをご希望ですか?
ワークフローでも「テキスト抽出」ノードを入れるとうまくいく
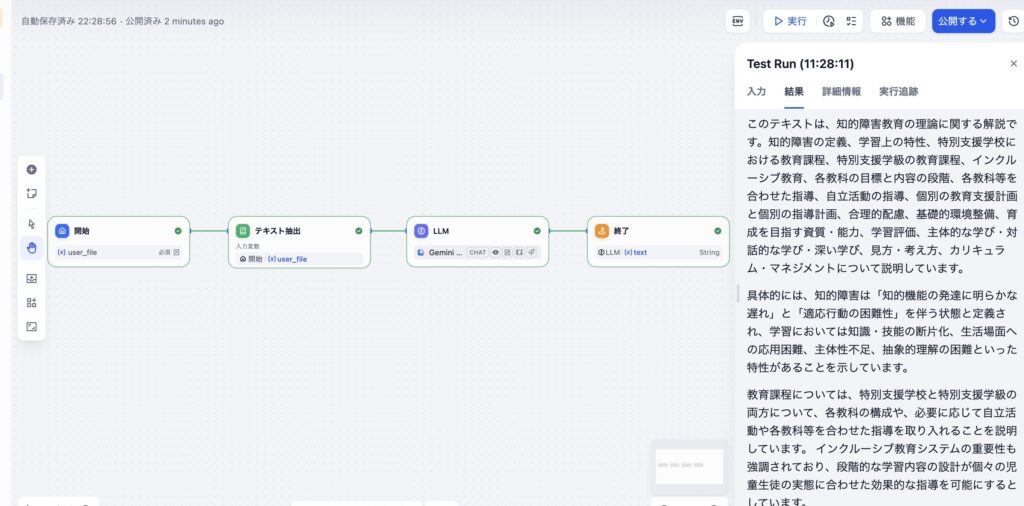
 弟子
弟子このときPDFはテキスト化されている必要があります。






コメント